A few links that explain Haskell much more than I do:
Haskell.org
The official Haskell website; download the latest version of the compiler (which actually just came out a few days ago), look at the documentation, find some silly Haskell humor. (No, seriously. There really is a humor section.)
Learn You a Haskell for Great Good!
An entertaining tutorial featuring silly drawings.
Real World Haskell
An online version of the book "Real World Haskell." Covers more than Learn You a Haskell for Great Good!, but is also much less funny.
Monad Tutorials Which Are Probably Better Than Mine:
A First Step Into Monads
(The rest of the Haskell posts on this blog are also recommended)
You Could Have Invented Monads! (And Maybe You Already Have)
Friday, December 18, 2009
Saturday, November 14, 2009
ID3 tags, revised
The program I put up last post works - sort of. There are a couple problems with it. First, it only handles three specific tags. Second, it doesn't actually use the information about the tag size that's in the tag itself. Third, it only works for version 2.2 tags. I've fixed all those issues in this. The new code is here. I'll go over a couple things in there that I haven't mentioned before.
(Line 91) ord lives in Data.Char; it converts a character to its numeric equivalent (i.e. ord 'A' is 65). toInteger converts values of Integral types to Integer values.
(Line 114, among others) let essentially binds a value to a name only for the duration of the statement following "in." (Note that if you're using GHCI, let is used to bind a value for the duration of the session.)
Out program now mostly works. We can run it on a file with version 2.3 ID3 tags:
The information is all correct; this file contains "Meet The Elements" from the newest They Might Be Giants album, Here Comes Science. (I assume it also works on version 2.4 tags, but I don't have any conveniently-located files that have them.)
Now, notice those ??'s? And remember how I said that this program mostly works? The text tags in this file are in Unicode. (I believe it's UTF-16 big-endian, to be specific) Right now, the program disregards the encoding bytes, and assumes everything uses ISO-8859-1. Next step: fixing this.
charToInteger x = (toInteger . ord) x
(Line 91) ord lives in Data.Char; it converts a character to its numeric equivalent (i.e. ord 'A' is 65). toInteger converts values of Integral types to Integer values.
let . . . in . . .
(Line 114, among others) let essentially binds a value to a name only for the duration of the statement following "in." (Note that if you're using GHCI, let is used to bind a value for the duration of the session.)
Out program now mostly works. We can run it on a file with version 2.3 ID3 tags:
Composer: ??
Title: ??Meet The Elements
Copyright message: ??(C) 2009 Disney
Content type: ??Children's Music
Artist: ??They Might Be Giants
Conductor/Performer refinement: ??
Album title: ??Here Comes Science (Amazon MP3 Exclusive Version)
Language code: eng
Content descriptor: ?
Contents: ??Amazon.com Song ID: 212903562
Track number: ??2/20
Accompanied by: ??They Might Be Giants
Part of a set: ??1/1
Year: ??2009
The information is all correct; this file contains "Meet The Elements" from the newest They Might Be Giants album, Here Comes Science. (I assume it also works on version 2.4 tags, but I don't have any conveniently-located files that have them.)
Now, notice those ??'s? And remember how I said that this program mostly works? The text tags in this file are in Unicode. (I believe it's UTF-16 big-endian, to be specific) Right now, the program disregards the encoding bytes, and assumes everything uses ISO-8859-1. Next step: fixing this.
Sunday, November 1, 2009
A little more monad, and a semi-useful program
Okay, first, addressing a couple points from the comments on my previous post.
StdGen is not a monad (something I probably should have made a bit clearer). However, the way StdGen works is similar to the way monads work - they share the idea of replacing a change in the state of something with returning a value representing the new state.
I admit, the input-reversing program isn't done in the "right" way, but I've got to mention return somewhere.
A Semi-Useful Program!
It's nice to know that you can write a program that reverses its input, but it's not especially useful. So it's time to write something that is sort of useful. What will this program do? It's going to extract some information from an MP3's ID3 tags.
A quick overview: MP3 files commonly include information on the song they contain. This information is in the file in the form of an ID3 tag. It's not encoded in any special way; we can see it fairly easily by opening the file in a hex editor. Here's an example:
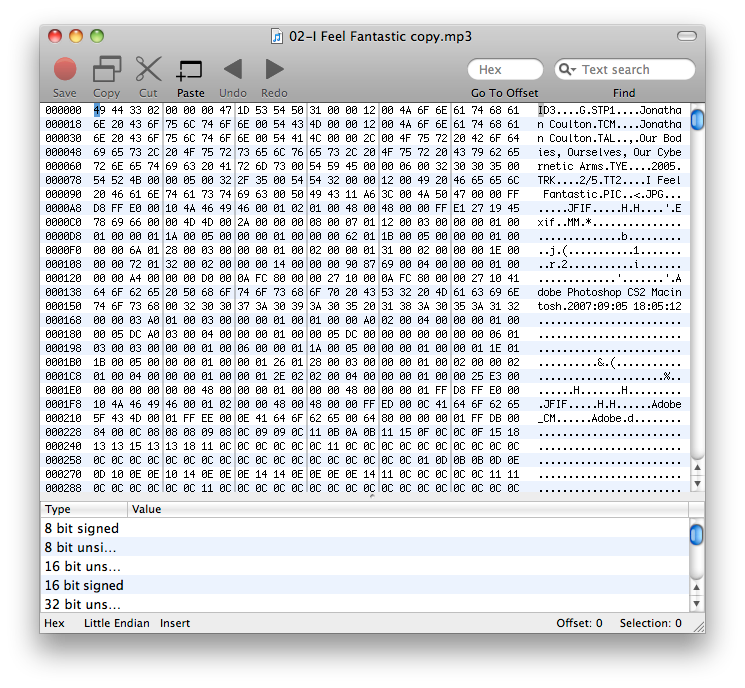
This particular file contains the song "I Feel Fantastic," by Jonathan Coulton. (It's a good song.) You can see an album name ("Our Bodies, Ourselves, Our Cybernetic Arms"), the artist's name, the composer's name (the previous two are the same in this case), the track title, the year of release, and the track's position on the album. You can also see the beginning of an image file inside the MP3. ID3 tags can also include information like genre, track length, or beats per minute. When you open an MP3 in iTunes, Winamp, or whatever program you use for that sort of thing, the ID3 tags are where the program gets its information about the song.
The length of the ID3 header is in the tags. However, it's in there in a rather bizarre way (28 bits - 4 bytes, disregarding the high bit of each, which is always zero), so we're going to cheat a bit. First, we're only going to look at three tags - track title, artist name, and album title. Second, instead of using the length information that's in the tags themselves, we're going to take advantage of the fact that each tag containing text is terminated with a zero byte (0x00).
In the screenshot, you'll notice, among others, three specific sequences of 3 characters: TP1, TAL, and TT2. These indicate the track title, album title, and artist name, respectively.
First, we need to read the file in somehow. For this, we'll use the functions getArgs, openFile, and hGetContents. getArgs lives in the System.Environment package. Its type is IO [String] - an IO monad carrying a list of Strings. These strings are any arguments supplied to the program from the command line.
openFile is from the package System.IO. The type looks like this:
FilePath is the same thing as String. The IOMode parameter tells the function whether we're going to be reading, writing, or both. A Handle is sort of like a Haskell representation of the file (the details aren't especially important here).
Finally, we'll look at hGetContents, also from System.IO.
hGetContents takes a Handle to a file, and returns an IO monad carrying the entire contents of that file in a String. Normally, this might be a bit inefficient. However, because Haskell is lazy, none of the contents of the file will actually be retrieved until we need them.
To understand the rest of the program, you'll also need to know a few more things.
tails: This function takes a list, and returns a list of all suffixes of that list. For example, tails [1,2,3,4] is [[1,2,3,4],[2,3,4],[3,4],[4]]. In a lot of languages, running this on a very large list (such as the contents of a file) might be very inefficient. However, again, because Haskell is lazy, nothing in the list tails gives you is evaluated until it's needed.
isPrefixOf is fairly self-explanatory; it takes two lists, and returns True if the first is a prefix of the second, False otherwise.
filter takes two arguments: a function from some type to a Boolean, and a list of things of that type. It returns the elements from the list for which the function evaluates to True.
Finally, handle. This function takes two arguments. The first is a function from some exception type to an IO monad. The second is an IO monad of the same type. When handle is called, it tries to evaluate the second argument. If an exception occurs, it passes the exception to the function and returns what it gets back. Otherwise, it just returns that second argument. (That's probably not very clear. It's essentially "Try to do something (the second parameter). If you fail for some reason, do this first parameter instead.")
Finally finally, two dashes are used to indicate comments.
So, here's the code:
NOTE: This program as written works only for ID3 version 2.2. Versions 2.3 and 2.4 use different identifiers for the frames and a slightly different frame header format. To make the program work for versions 2.3 and 2.4 instead, make the following changes:
In line 7, replace "TAL" with "TALB"
In line 8, replace "TT2" with "TIT2"
In line 9, replace "TP1" with "TPE1"
In lines 12, 15, and 18, replace "7" with "9"
(Disclaimer: I haven't tested this modified version)
After compiling, I can run it, and it looks like this:
Or, I can give it something that doesn't have ID3 tags. Obviously the compiled program itself won't have any, so let's try that:
Finally, I made a file that starts with "ID3" (the program's method for determining if there might be tags) but contains no tags. (I basically just typed "ID3" and then banged on the keyboard like a monkey for a bit.) We can run the program on that, and get this:
StdGen is not a monad (something I probably should have made a bit clearer). However, the way StdGen works is similar to the way monads work - they share the idea of replacing a change in the state of something with returning a value representing the new state.
I admit, the input-reversing program isn't done in the "right" way, but I've got to mention return somewhere.
A Semi-Useful Program!
It's nice to know that you can write a program that reverses its input, but it's not especially useful. So it's time to write something that is sort of useful. What will this program do? It's going to extract some information from an MP3's ID3 tags.
A quick overview: MP3 files commonly include information on the song they contain. This information is in the file in the form of an ID3 tag. It's not encoded in any special way; we can see it fairly easily by opening the file in a hex editor. Here's an example:

This particular file contains the song "I Feel Fantastic," by Jonathan Coulton. (It's a good song.) You can see an album name ("Our Bodies, Ourselves, Our Cybernetic Arms"), the artist's name, the composer's name (the previous two are the same in this case), the track title, the year of release, and the track's position on the album. You can also see the beginning of an image file inside the MP3. ID3 tags can also include information like genre, track length, or beats per minute. When you open an MP3 in iTunes, Winamp, or whatever program you use for that sort of thing, the ID3 tags are where the program gets its information about the song.
The length of the ID3 header is in the tags. However, it's in there in a rather bizarre way (28 bits - 4 bytes, disregarding the high bit of each, which is always zero), so we're going to cheat a bit. First, we're only going to look at three tags - track title, artist name, and album title. Second, instead of using the length information that's in the tags themselves, we're going to take advantage of the fact that each tag containing text is terminated with a zero byte (0x00).
In the screenshot, you'll notice, among others, three specific sequences of 3 characters: TP1, TAL, and TT2. These indicate the track title, album title, and artist name, respectively.
First, we need to read the file in somehow. For this, we'll use the functions getArgs, openFile, and hGetContents. getArgs lives in the System.Environment package. Its type is IO [String] - an IO monad carrying a list of Strings. These strings are any arguments supplied to the program from the command line.
openFile is from the package System.IO. The type looks like this:
> import System.IO
> :t openFile
openFile :: FilePath -> IOMode -> IO Handle
FilePath is the same thing as String. The IOMode parameter tells the function whether we're going to be reading, writing, or both. A Handle is sort of like a Haskell representation of the file (the details aren't especially important here).
Finally, we'll look at hGetContents, also from System.IO.
> import System.IO
> :t hGetContents
hGetContents :: Handle -> IO String
hGetContents takes a Handle to a file, and returns an IO monad carrying the entire contents of that file in a String. Normally, this might be a bit inefficient. However, because Haskell is lazy, none of the contents of the file will actually be retrieved until we need them.
To understand the rest of the program, you'll also need to know a few more things.
tails: This function takes a list, and returns a list of all suffixes of that list. For example, tails [1,2,3,4] is [[1,2,3,4],[2,3,4],[3,4],[4]]. In a lot of languages, running this on a very large list (such as the contents of a file) might be very inefficient. However, again, because Haskell is lazy, nothing in the list tails gives you is evaluated until it's needed.
isPrefixOf is fairly self-explanatory; it takes two lists, and returns True if the first is a prefix of the second, False otherwise.
filter takes two arguments: a function from some type to a Boolean, and a list of things of that type. It returns the elements from the list for which the function evaluates to True.
Finally, handle. This function takes two arguments. The first is a function from some exception type to an IO monad. The second is an IO monad of the same type. When handle is called, it tries to evaluate the second argument. If an exception occurs, it passes the exception to the function and returns what it gets back. Otherwise, it just returns that second argument. (That's probably not very clear. It's essentially "Try to do something (the second parameter). If you fail for some reason, do this first parameter instead.")
Finally finally, two dashes are used to indicate comments.
So, here's the code:
import Control.Exception
import Data.List
import System.Environment
import System.IO
--Relevant frame name constants
albumFrame = "TAL"
titleFrame = "TT2"
artistFrame = "TP1"
extractArtist :: [Char] -> [Char]
extractArtist file = readUntilZero (drop 7 (file `cutBefore` artistFrame))
extractTitle :: [Char] -> [Char]
extractTitle file = readUntilZero (drop 7 (file `cutBefore` titleFrame))
extractAlbum :: [Char] -> [Char]
extractAlbum file = readUntilZero (drop 7 (file `cutBefore` albumFrame))
readUntilZero :: [Char] -> [Char]
readUntilZero [] = []
readUntilZero ('\0':xs) = []
readUntilZero (x:xs) = x:(readUntilZero xs)
cutBefore :: [Char] -> [Char] -> [Char]
cutBefore str substr = (filter (isPrefixOf substr) (tails str)) !! 0
main = do
(fName:otherArgs) <- getArgs
inHandle <- openFile fName ReadMode
fContents <- hGetContents inHandle
if ("ID3" `isPrefixOf` fContents)
then do
handle ((\_ -> putStrLn "Title Not Found")::SomeException -> IO()) (putStrLn ("Title: " ++ (extractTitle fContents)))
handle ((\_ -> putStrLn "Album Not Found")::SomeException -> IO()) (putStrLn ("Album: " ++ (extractAlbum fContents)))
handle ((\_ -> putStrLn "Artist Not Found")::SomeException -> IO()) (putStrLn ("Artist: " ++ (extractArtist fContents)))
else putStrLn("No ID3 tags detected")
NOTE: This program as written works only for ID3 version 2.2. Versions 2.3 and 2.4 use different identifiers for the frames and a slightly different frame header format. To make the program work for versions 2.3 and 2.4 instead, make the following changes:
In line 7, replace "TAL" with "TALB"
In line 8, replace "TT2" with "TIT2"
In line 9, replace "TP1" with "TPE1"
In lines 12, 15, and 18, replace "7" with "9"
(Disclaimer: I haven't tested this modified version)
After compiling, I can run it, and it looks like this:
noethers-imac:Haskell noether$ ./id3reader "02-I Feel Fantastic copy.mp3"
Title: I Feel Fantastic
Album: Our Bodies, Ourselves, Our Cybernetic Arms
Artist: Jonathan Coulton
Or, I can give it something that doesn't have ID3 tags. Obviously the compiled program itself won't have any, so let's try that:
noethers-imac:Haskell noether$ ./id3reader id3reader
No ID3 tags detected
Finally, I made a file that starts with "ID3" (the program's method for determining if there might be tags) but contains no tags. (I basically just typed "ID3" and then banged on the keyboard like a monkey for a bit.) We can run the program on that, and get this:
noethers-imac:Haskell noether$ ./id3reader fakeTag.txt
Title Not Found
Album Not Found
Artist Not Found
Thursday, October 29, 2009
How do I compile, and what the heck is a monad, anyway?
Compiling
So you've written a Haskell program. It's the most fantastically awesome thing ever saved to a hard drive. It will surely make you millions of dollars. But there's a problem. How do you compile it?
Fortunately, compiling is very simple. Just do like so from a terminal:
(.hs is a commonly-used extension for Haskell source code files.)
Much like gcc, this will compile the source in foo.hs to a.out. If you want a slightly more informative file name, you can use the -o flag, like so:
This will compile foo.hs to the file bar.
What's this monad thing?
Monads are weird. There's really no better word for them. You see, functions in pure functional languages aren't supposed to have any side effects. They're supposed to return a value and do nothing else. This means that, technically, a pure functional language can't do some of those less important things - you know, things that nobody ever uses. Things like random numbers. Things like I/O.
Fortunately, being a bunch of really smart guys, the creators of Haskell decided this was ridiculous. The solution to this problem? Monads. Monads allow Haskell to do things like I/O that pure functional languages can't normally do. Random numbers can be handled without monads, but we'll start with them anyway.
In the Random package, there's a function called mkStdGen. It takes an Integer seed and returns a StdGen (a specific implementation of a random number generator) with that seed. There's also a function called next. Let's look at the type.
In both the interactive shell and programs to be compiled, you can bring in external packages with import.
RandomGen is a type class for generators of random stuff. (Surprising, I know.) The next function takes a random generator and returns a pair containing a number (your random number) and a new random generator. This new random generator is the key.
In a language like C++ or Java, the next function would return only the number, and modify the existing random number generator. In Haskell, we can't do that; that would be a side effect. So, instead of modifying the generator, we just make a new one. It essentially works like this: instead of modifying the current generator so it will produce the next number in the sequence on the next call, we create a new one which will produce the next number in the sequence.
That's basically how monads work. Instead of modifying the state (which we aren't allowed to do), we pass it in as a parameter, and get a new one out as a result. For the remainder of this post, I'll be mostly looking at the IO monad. This monad lets us essentially treat I/O actions like variables.
Let's look at the type of the function putStrLn, which prints a String to the console.
Notice those parentheses? IO isn't a single type; it's a whole group of them. (This isn't specific to IO; it's the case with all monads in Haskell.) That part of the type signature after the arrow is a type constructor. In this case, it's creating an IO monad that carries no additional information. Compare that to the type signature of another function, getLine. This one reads a line from the console.
getLine takes no parameters, and returns an IO monad carrying a String with it. Let's look at a simple Haskell program using these two functions.
First, the backslash. This is used for lambda expressions - basically functions that are defined inline. That >>= works somewhat like bash's pipe. It passes the value returned by the first function to the second. If you have a lot of actions, this could get unwieldy, so Haskell provides an alternative syntax:
Do hooks everything following it together with >>=, with the added benefit of being able to bind values to names (That's what the <- does.). This program will read a line from the console and print it back. Now, let's try something a bit more complicated.
Looking at it, it should do the same thing as the last program, except it should print the line back reversed. However, if we try to compile this, we get an error:
Everything in a do expression must be monadic. So how do we include the results of non-monadic functions? We do this:
See return? It does not do what Java or C's return does. Take a look at the type:
Monad is a type class; it should be pretty obvious what kind of types it contains. So return takes a something with type a, and gives back a monad containing something with type a. In fact, these two "somethings" are the same something. Return wraps a value in a monad so it can be used in a monadic sequence.
So you've written a Haskell program. It's the most fantastically awesome thing ever saved to a hard drive. It will surely make you millions of dollars. But there's a problem. How do you compile it?
Fortunately, compiling is very simple. Just do like so from a terminal:
ghc foo.hs
(.hs is a commonly-used extension for Haskell source code files.)
Much like gcc, this will compile the source in foo.hs to a.out. If you want a slightly more informative file name, you can use the -o flag, like so:
ghc -o bar foo.hs
This will compile foo.hs to the file bar.
What's this monad thing?
Monads are weird. There's really no better word for them. You see, functions in pure functional languages aren't supposed to have any side effects. They're supposed to return a value and do nothing else. This means that, technically, a pure functional language can't do some of those less important things - you know, things that nobody ever uses. Things like random numbers. Things like I/O.
Fortunately, being a bunch of really smart guys, the creators of Haskell decided this was ridiculous. The solution to this problem? Monads. Monads allow Haskell to do things like I/O that pure functional languages can't normally do. Random numbers can be handled without monads, but we'll start with them anyway.
In the Random package, there's a function called mkStdGen. It takes an Integer seed and returns a StdGen (a specific implementation of a random number generator) with that seed. There's also a function called next. Let's look at the type.
> import Random
> :t next
next :: (RandomGen g) => g -> (Int, g)
In both the interactive shell and programs to be compiled, you can bring in external packages with import.
RandomGen is a type class for generators of random stuff. (Surprising, I know.) The next function takes a random generator and returns a pair containing a number (your random number) and a new random generator. This new random generator is the key.
In a language like C++ or Java, the next function would return only the number, and modify the existing random number generator. In Haskell, we can't do that; that would be a side effect. So, instead of modifying the generator, we just make a new one. It essentially works like this: instead of modifying the current generator so it will produce the next number in the sequence on the next call, we create a new one which will produce the next number in the sequence.
That's basically how monads work. Instead of modifying the state (which we aren't allowed to do), we pass it in as a parameter, and get a new one out as a result. For the remainder of this post, I'll be mostly looking at the IO monad. This monad lets us essentially treat I/O actions like variables.
Let's look at the type of the function putStrLn, which prints a String to the console.
> :t putStrLn
putStrLn :: String -> IO ()
Notice those parentheses? IO isn't a single type; it's a whole group of them. (This isn't specific to IO; it's the case with all monads in Haskell.) That part of the type signature after the arrow is a type constructor. In this case, it's creating an IO monad that carries no additional information. Compare that to the type signature of another function, getLine. This one reads a line from the console.
> :t getLine
getLine :: IO String
getLine takes no parameters, and returns an IO monad carrying a String with it. Let's look at a simple Haskell program using these two functions.
main = (getLine) >>= (\x -> putStrLn x)
First, the backslash. This is used for lambda expressions - basically functions that are defined inline. That >>= works somewhat like bash's pipe. It passes the value returned by the first function to the second. If you have a lot of actions, this could get unwieldy, so Haskell provides an alternative syntax:
main = do
x <- getLine
putStrLn x
Do hooks everything following it together with >>=, with the added benefit of being able to bind values to names (That's what the <- does.). This program will read a line from the console and print it back. Now, let's try something a bit more complicated.
main = do
x <- getLine
x1 <- reverse x
putStrLn x1
Looking at it, it should do the same thing as the last program, except it should print the line back reversed. However, if we try to compile this, we get an error:
cat.hs:3:1:
Couldn't match expected type `[Char]'
against inferred type `IO Char'
In a stmt of a 'do' expression: x1 <- reverse x
In the expression:
do x <- getLine
x1 <- reverse x
putStrLn x1
In the definition of `main':
main = do x <- getLine
x1 <- reverse x
putStrLn x1
Everything in a do expression must be monadic. So how do we include the results of non-monadic functions? We do this:
main = do
x <- getLine
x1 <- return (reverse x)
putStrLn x1
See return? It does not do what Java or C's return does. Take a look at the type:
> :t return
return :: (Monad m) => a -> m a
Monad is a type class; it should be pretty obvious what kind of types it contains. So return takes a something with type a, and gives back a monad containing something with type a. In fact, these two "somethings" are the same something. Return wraps a value in a monad so it can be used in a monadic sequence.
Tuesday, October 20, 2009
Functions
Yes, it's time to do some actual programming! Cue applause and confetti.
We'll start with one of everybody's favorites, the factorial. In fact, we'll do it several ways. We'll start with a one-liner. You'll just need to remember two things: ranges, and the product function. Our first factorial function looks like this:
Note that we don't need any silly complicated stuff like "let," or "def," or "public static int." Just function name, parameters, what you get. Now, if you're doing this in the interactive shell, you will need a "let." I think a demonstration is in order.
Haskell has arbitrary-precision integers for happy fun times.
Note the way we call the function. We don't need any parentheses, just the function and its argument. Now, if you're nesting function calls, you probably will want to include parentheses to clarify order of operations. Like so:
Hokay, moving on. Factorial function number two:
Foldl is a very common function in functional languages. It's what's known as a higher-order function - a function that takes another function as a parameter. Let's take a look at foldl's type.
Notice that first part in parentheses? The first parameter to foldl is a function. In our case, we're using the * function. (We need to enclose it in parentheses because it's an infix function.) Foldl basically takes a function, an initial value, and a list, and combines the initial value and everything in the list together using the function. It does this by putting the initial value and every element from the list in a line, putting the function between every pair, and associating to the left. (There's another function, foldr, that associates to the right.) So when we call, say, this:
We're essentially doing this:
Moving on, a minor modification. Let's call it factorial program 2.5.
The foldl1 function is identical to foldl, except it doesn't need an initial value; it just uses the first element of the list.
Moving on, we come to one of Haskell's most powerful features: pattern matching.
You're likely familiar with C or Java's switch statement, Ruby's case statement, or maybe even Perl's given. Pattern matching is a souped-up version of this. To the example! (We'll also use recursion!)
When you call this version of the factorial program, Haskell will run through the lines in order, checking for one that matches what you called. If you used 0 as your parameter, then that's easy! 0! is 1, it says so right there! If you didn't use 0, then whatever you used is n, right? So multiply n by (n-1)!, and there you go. For a slightly more complicated example, we can also do Fibonacci numbers:
(There's actually a much cooler way to do the Fibonacci sequence, which I'll cover later.)
With pattern matching, we can do things like implementing foldl:
The apostrophe is a legal character in function names. In the (x:xs) pattern, x is the first element of the list and xs is the rest.
Now we can implement foldl1 in terms of our foldl1' function.
We can implement product specifically:
Or we can implement it with foldl1:
Haskell has a built-in function called zipWith, which takes a function and two lists, and combines the lists by applying the function to corresponding elements. So, for example, we can do:
Let's reimplement zipWith. Start by looking at the type:
So we'll need three parameters: a function and two lists. We start with the base case: if we combine two empty lists, we obviously get an empty list. So we can start with
If we have a list with elements, we want to combine the first elements of each list, put it at the front of the result list, and add the combinations of the rest of the elements. So we do this:
Now, add a type header (you don't actually have to do this, but it can make things nicer) and put it all together:
Remember I said there was a really cool way to do the Fibonacci sequence? Here it is.
That's the entire Fibonacci sequence. The whole thing. Remember that Haskell is lazy, so it won't evaluate anything in the list until it needs to.
Let's finish with one more common one: the quicksort. First, let's figure out the type. We start with a list of things, and end with a list of things of the same type. The things also have to be comparable. So our type is this:
We'll start with our base cases. Obviously, a one-element list and an empty list are already sorted.
If we have multiple elements, we select a pivot (we'll use the first element of the list), sort the stuff lower than the pivot, add on the pivot, then sort the stuff higher than the pivot.
Put it all together:
We'll start with one of everybody's favorites, the factorial. In fact, we'll do it several ways. We'll start with a one-liner. You'll just need to remember two things: ranges, and the product function. Our first factorial function looks like this:
fact n = product [1..n]
Note that we don't need any silly complicated stuff like "let," or "def," or "public static int." Just function name, parameters, what you get. Now, if you're doing this in the interactive shell, you will need a "let." I think a demonstration is in order.
> let fact n = product [1..n]
> fact 5
120
> fact 12
479001600
> fact 147
172724589045463891120349865930862023193347650359789782279909232218331909803632016425196
730421051185517193022186186753141552289286530880054617437418211264485685176226179744177
18521481737240752909004600275325629858346067558400000000000000000000000000000000000
Haskell has arbitrary-precision integers for happy fun times.
Note the way we call the function. We don't need any parentheses, just the function and its argument. Now, if you're nesting function calls, you probably will want to include parentheses to clarify order of operations. Like so:
> fact (fact 5)
668950291344912705758811805409037258675274633313802981029567135230163355724496298936687
416527198498130815763789321409055253440858940812185989848111438965000596496052125696000
0000000000000000000000000
Hokay, moving on. Factorial function number two:
fact n = foldl (*) 1 [1..n]
Foldl is a very common function in functional languages. It's what's known as a higher-order function - a function that takes another function as a parameter. Let's take a look at foldl's type.
> :t foldl
foldl :: (a -> b -> a) -> a -> [b] -> a
Notice that first part in parentheses? The first parameter to foldl is a function. In our case, we're using the * function. (We need to enclose it in parentheses because it's an infix function.) Foldl basically takes a function, an initial value, and a list, and combines the initial value and everything in the list together using the function. It does this by putting the initial value and every element from the list in a line, putting the function between every pair, and associating to the left. (There's another function, foldr, that associates to the right.) So when we call, say, this:
foldl (+) 0 [1..5]
We're essentially doing this:
((((0+1)+2)+3)+4)+5
Moving on, a minor modification. Let's call it factorial program 2.5.
fact n = foldl1 (*) [1..n]
The foldl1 function is identical to foldl, except it doesn't need an initial value; it just uses the first element of the list.
Moving on, we come to one of Haskell's most powerful features: pattern matching.
You're likely familiar with C or Java's switch statement, Ruby's case statement, or maybe even Perl's given. Pattern matching is a souped-up version of this. To the example! (We'll also use recursion!)
fact 0 = 1
fact n = n * fact (n-1)
When you call this version of the factorial program, Haskell will run through the lines in order, checking for one that matches what you called. If you used 0 as your parameter, then that's easy! 0! is 1, it says so right there! If you didn't use 0, then whatever you used is n, right? So multiply n by (n-1)!, and there you go. For a slightly more complicated example, we can also do Fibonacci numbers:
fib 0 = 1
fib 1 = 1
fib n = fib (n-1) + fib (n-2)
(There's actually a much cooler way to do the Fibonacci sequence, which I'll cover later.)
With pattern matching, we can do things like implementing foldl:
foldl' :: (a -> b -> a) -> a -> [b] -> a
foldl' f i [] = i
foldl' f i (x:xs) = foldl' f (f i x) xs
The apostrophe is a legal character in function names. In the (x:xs) pattern, x is the first element of the list and xs is the rest.
Now we can implement foldl1 in terms of our foldl1' function.
foldl1' :: (a -> a -> a) -> [a] -> a
foldl1' f (x:xs) = foldl f x xs
We can implement product specifically:
product' :: (Num a) => [a] -> a
product' [x] = x
product' (x:xs) = x * product' xs
Or we can implement it with foldl1:
product' :: (Num a) => [a] -> a
product' xs = foldl1 (*) xs
Haskell has a built-in function called zipWith, which takes a function and two lists, and combines the lists by applying the function to corresponding elements. So, for example, we can do:
> zipWith (*) [1..10] [2..11]
[2,6,12,20,30,42,56,72,90,110]
Let's reimplement zipWith. Start by looking at the type:
> :t zipWith
zipWith :: (a -> b -> c) -> [a] -> [b] -> [c]
So we'll need three parameters: a function and two lists. We start with the base case: if we combine two empty lists, we obviously get an empty list. So we can start with
zipWith' f [] [] = []
If we have a list with elements, we want to combine the first elements of each list, put it at the front of the result list, and add the combinations of the rest of the elements. So we do this:
zipWith' f (a:as) (b:bs) = (f a b):(zipWith' f as bs)
Now, add a type header (you don't actually have to do this, but it can make things nicer) and put it all together:
zipWith' :: (a -> b -> c) -> [a] -> [b] -> [c]
zipWith' f [] [] = []
zipWith' f (a:as) (b:bs) = (f a b):(zipWith' f as bs)
Remember I said there was a really cool way to do the Fibonacci sequence? Here it is.
fibonacci = 0 : 1 : (zipWith (+) fibonacci (tail fibonacci))
That's the entire Fibonacci sequence. The whole thing. Remember that Haskell is lazy, so it won't evaluate anything in the list until it needs to.
Let's finish with one more common one: the quicksort. First, let's figure out the type. We start with a list of things, and end with a list of things of the same type. The things also have to be comparable. So our type is this:
(Ord t) => [t] -> [t]
We'll start with our base cases. Obviously, a one-element list and an empty list are already sorted.
quicksort [] = []
quicksort [x] = [x]
If we have multiple elements, we select a pivot (we'll use the first element of the list), sort the stuff lower than the pivot, add on the pivot, then sort the stuff higher than the pivot.
quicksort (x:xs) = (quicksort [ a | a <- xs, a < x]) ++ [x] ++ (quicksort [a | a <- xs, a >= x])
Put it all together:
quicksort :: (Ord t) => [t] -> [t]
quicksort [] = []
quicksort [x] = [x]
quicksort (x:xs) = (quicksort [ a | a <- xs, a < x]) ++ [x] ++ (quicksort [a | a <- xs, a >= x])
Friday, October 16, 2009
Lists, ranges, and tuples
Okay, so you want to store multiple values in one variable. (Yes, you do. Don't question it.) So, of course, you use an array. In Haskell, you have two choices: you can use a list or a tuple.
Lists
A list is essentially what any non-functional language would call an array. It's an ordered set of values of the same type. List literals are set off by brackets, like so:
Checking the type tells you this:
Recall from the last post that, without any context, numbers are just some kind of number. [t] is Haskell's notation for a list of things of type t. Let's play around a bit more.
Remember that in Haskell a string is nothing more than a list of characters.
And, of course, we can nest lists for crazy fun times.
We've also got a few list functions to play with. Like these:
List concatenation:
The cons operator:
The cons operator takes a thing and a list of other things of the same type, and sticks the first thing on the front of the list. It's fast.
Obviously, you might want to access individual values in a list. You can do that, too!
The indices are zero-based.
Those four functions return the first element, everything except the first element, everything except the last element, and the last element, respectively. Don't use these on empty lists.
Yeah, Haskell doesn't like that.
These next functions do exactly what they sound like they do.
Note that the minimum and maximum functions can be used on lists of anything that has an order - i.e. anything in the type class Ord
Here are a few more that might require a bit of explanation.
This function gives you a number of elements off the front of the list. If the number you give is bigger than the length of the list, you get the whole thing.
This function cuts a number off the front of the list and gives you the rest. If the number you give is bigger than the length of the list, you get an empty list.
This function evaluates to True if and only if you give it an empty list.
Pretty straightforward; True if the first argument is an element of the second, False otherwise. The first does need to be the same type as the elements of the second, or Haskell will complain. ProTip: Pretty much every two-argument function can be used as an infix function by enclosing it in backticks.
There are also a couple built-in arithmetic list functions. These are self-explanatory.
Haskell is lazy. This means it doesn't actually evaluate anything until you want to do something with it. This means that we can do infinite lists!
This function will produce an infinite list out of any list by repeating it over and over. If you try to display it, it will never end. We can get around this by just displaying the first few elements, like so:
If you want to repeat just one element, there's a separate function for that. (You can use cycle if you want, though.)
Now, sometimes you might want a list like [1,2,3,4,5,6,7,8,9]. Of course, you don't want to type out that whole thing every time. Fortunately for you, Haskell gives you a shortcut: ranges.
Ranges
If you want a list where the elements are consecutive, you can use a range. Like so:
You can use ranges with anything in the type class Enum - like Chars.
The elements don't actually have to be consecutive; the distance between elements just needs to be constant. You can specify this like so:
We can also count down.
You can also use ranges to make infinite lists. All you have to do is not specify an upper limit. Like this:
Now, remember set-builder notation from math? The one with the curly braces? We can do that in Haskell! They're called list comprehensions.
List Comprehensions
List comprehensions basically work like this: You specify which things you want to do stuff two, and you specify what you want to do to them. Like this:
That first line basically says this: A list of x-squared, where x is drawn from the list of things from 1 to 10. You can do interesting things with this. Like this:
Remember that the succ function takes a value and evaluates to whatever value comes next. We'll do more cool stuff with list comprehensions later. But first, what if you want to store a bunch of things of different types in one variable? Yes, Haskell can do that too. You can use tuples.
Tuples
A tuple is basically a set of variables. They're set off with parentheses. Like this:
The type of a tuple is also set off with parentheses, like so:
You can nest tuples and lists, so you could create a bizarre monstrosity with a type like this:
That would be a list of tuples, each composed of two elements: a list of tuples, each containing a list of characters and a number, and a boolean.
A tuple containing two values is called a pair, and there are two special functions that you can use on them:
That's the first and second value in the tuple, respectively.
Remember, the difference between a tuple and a list: A list is a set of no specific size where the elements are all the same type; a tuple is a set of specific size where the elements can be of different types.
Next time, we'll finally do some actual coding! (Well, I will. I can't guarantee that you will.)
Lists
A list is essentially what any non-functional language would call an array. It's an ordered set of values of the same type. List literals are set off by brackets, like so:
[1,2,4]
Checking the type tells you this:
> :t [1,2,4]
[1,2,4] :: (Num t) => [t]
Recall from the last post that, without any context, numbers are just some kind of number. [t] is Haskell's notation for a list of things of type t. Let's play around a bit more.
> :t ['D', 'e', 'a', 'd']
['D', 'e', 'a', 'd'] :: [Char]
> :t "prosthetic forehead"
"prosthetic forehead" :: [Char]
Remember that in Haskell a string is nothing more than a list of characters.
And, of course, we can nest lists for crazy fun times.
> :t [[1,2,3],[4,5,6]]
[[1,2,3],[4,5,6]] :: (Num t) => [[t]]
We've also got a few list functions to play with. Like these:
List concatenation:
> [1,2,3] ++ [4,5,6]
[1,2,3,4,5,6]
The cons operator:
> 1:[2,4,8]
[1,2,4,8]
The cons operator takes a thing and a list of other things of the same type, and sticks the first thing on the front of the list. It's fast.
Obviously, you might want to access individual values in a list. You can do that, too!
> "rock to wind a piece of string around" !! 8
'w'
The indices are zero-based.
> head "Istanbul"
'I'
> tail "Istanbul"
"stanbul"
> init "Istanbul"
"Istanbu"
> last "Istanbul"
'l'
Those four functions return the first element, everything except the first element, everything except the last element, and the last element, respectively. Don't use these on empty lists.
> head []
*** Exception: Prelude.head: empty list
Yeah, Haskell doesn't like that.
These next functions do exactly what they sound like they do.
> length "Letterbox"
9
> reverse "Particle Man"
"naM elcitraP"
> minimum [2,4,1,5,7,3]
1
> maximum [2,4,1,5,7,3]
7
Note that the minimum and maximum functions can be used on lists of anything that has an order - i.e. anything in the type class Ord
Here are a few more that might require a bit of explanation.
> take 5 "Sapphire Bullets of Pure Love"
"Sapph"
>take 5 "Dead"
"Dead"
This function gives you a number of elements off the front of the list. If the number you give is bigger than the length of the list, you get the whole thing.
> drop 6 "Your Racist Friend"
"acist Friend"
> drop 6 "Dead"
""
> drop 0 "Dead"
"Dead"
This function cuts a number off the front of the list and gives you the rest. If the number you give is bigger than the length of the list, you get an empty list.
> null "Lucky Ball and Chain"
False
> null []
True
This function evaluates to True if and only if you give it an empty list.
> 'Y' `elem` "Birdhouse In Your Soul"
True
> 'Y' `elem` "Dead"
False
Pretty straightforward; True if the first argument is an element of the second, False otherwise. The first does need to be the same type as the elements of the second, or Haskell will complain. ProTip: Pretty much every two-argument function can be used as an infix function by enclosing it in backticks.
There are also a couple built-in arithmetic list functions. These are self-explanatory.
> sum [1,5,3]
9
> product [1,5,3]
15
Haskell is lazy. This means it doesn't actually evaluate anything until you want to do something with it. This means that we can do infinite lists!
This function will produce an infinite list out of any list by repeating it over and over. If you try to display it, it will never end. We can get around this by just displaying the first few elements, like so:
> take 16 (cycle [1,2,4])
[1,2,4,1,2,4,1,2,4,1,2,4,1,2,4,1]
If you want to repeat just one element, there's a separate function for that. (You can use cycle if you want, though.)
> take 10 (repeat 5)
[5,5,5,5,5,5,5,5,5,5]
Now, sometimes you might want a list like [1,2,3,4,5,6,7,8,9]. Of course, you don't want to type out that whole thing every time. Fortunately for you, Haskell gives you a shortcut: ranges.
Ranges
If you want a list where the elements are consecutive, you can use a range. Like so:
> [1..20]
[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]
You can use ranges with anything in the type class Enum - like Chars.
> ['a'..'z']
"abcdefghijklmnopqrstuvwxyz"
The elements don't actually have to be consecutive; the distance between elements just needs to be constant. You can specify this like so:
> [2,4..20]
[2,4,6,8,10,12,14,16,18,20]
> ['b','d'..'z']
"bdfhjlnprtvxz"
> [3,9..99]
[3,9,15,21,27,33,39,45,51,57,63,69,75,81,87,93,99]
We can also count down.
> [20,19..1]
[20,19,18,17,16,15,14,13,12,11,10,9,8,7,6,5,4,3,2,1]
> ['z','y'..'a']
"zyxwvutsrqponmlkjihgfedcba"
> [20,18..2]
[20,18,16,14,12,10,8,6,4,2]
You can also use ranges to make infinite lists. All you have to do is not specify an upper limit. Like this:
> take 10 [8,26..]
[8,26,44,62,80,98,116,134,152,170]
Now, remember set-builder notation from math? The one with the curly braces? We can do that in Haskell! They're called list comprehensions.
List Comprehensions
List comprehensions basically work like this: You specify which things you want to do stuff two, and you specify what you want to do to them. Like this:
> [ x^2 | x <- [1..10] ]
[1,4,9,16,25,36,49,64,81,100]
That first line basically says this: A list of x-squared, where x is drawn from the list of things from 1 to 10. You can do interesting things with this. Like this:
> [succ x | x <- "Whistling In The Dark" ]
"Xijtumjoh!Jo!Uif!Ebsl"
Remember that the succ function takes a value and evaluates to whatever value comes next. We'll do more cool stuff with list comprehensions later. But first, what if you want to store a bunch of things of different types in one variable? Yes, Haskell can do that too. You can use tuples.
Tuples
A tuple is basically a set of variables. They're set off with parentheses. Like this:
> (19, "Road Movie To Berlin")
(19, "Road Movie To Berlin")
The type of a tuple is also set off with parentheses, like so:
> :t (19, "Road Movie To Berlin")
(19, "Road Movie To Berlin") :: (Num t) => (t, [Char])
You can nest tuples and lists, so you could create a bizarre monstrosity with a type like this:
(Num t) => [([([Char], t)], Bool)]
That would be a list of tuples, each composed of two elements: a list of tuples, each containing a list of characters and a number, and a boolean.
A tuple containing two values is called a pair, and there are two special functions that you can use on them:
> fst (5, "Dead")
5
> snd (5, "Dead")
"Dead"
That's the first and second value in the tuple, respectively.
Remember, the difference between a tuple and a list: A list is a set of no specific size where the elements are all the same type; a tuple is a set of specific size where the elements can be of different types.
Next time, we'll finally do some actual coding! (Well, I will. I can't guarantee that you will.)
Tuesday, October 13, 2009
Types and Type Classes
Important bit of info number one: Everything in Haskell has a type. (Except comments. That would be silly.)
Once you've got Haskell installed, you can run the interactive shell with ghci. Open that up. You should get some version info, some "I'm loading, hold your horses" kind of stuff, and then
(From here on, I'll just use > instead.)
Let's play around a bit.
Type in 3, you get 3. Not particularly exciting.
Slightly more interesting.
Tasty.
Now that's interesting. "What are you doing?!" Haskell cries. "Why do you try to add 3 to cake? What does that even mean, you very silly person?" Haskell complains because the type of the function + (Yes, it's a function. You can do anything with it that you can do with any other function) doesn't match what it sees. Important Bit Of Information Number 1a: Functions have types. In ghci, you can find the type of something with :t. Like so:
Okay, first, why + is in parentheses. It's an infix function, and those need to be in parentheses to be passed around. Now, to explain the second line.
First of all, Num. This is what's called a type class. Num is a class containing all the numeric types. (Num a) means that, for this type signature, a is a numeric type.
Let's play around a bit more with :t.
A character is denoted by single quotes.
That's a list of characters. In Haskell, there's no difference between this and a string. (More on lists later)
Without any context, 3 doesn't have a specific type. There are quite a few numeric types, and Haskell doesn't know which one we want, so, for now, it's just some kind of number.
succ is a function that takes a value and returns the next one. Enum is a type class containing types where "next value" actually means something. You can use these types in ranges (more on that later).
print does exactly what you think it does. Show is a typeclass containing things you can print. The weird part here is
< returns True if the first value is less, False otherwise. Bool is, obviously, the type for boolean values. Ord is the type class containing types whose values are in a defined order.
Once you've got Haskell installed, you can run the interactive shell with ghci. Open that up. You should get some version info, some "I'm loading, hold your horses" kind of stuff, and then
Prelude>
(From here on, I'll just use > instead.)
Let's play around a bit.
> 3
3
Type in 3, you get 3. Not particularly exciting.
> 3+4
7
Slightly more interesting.
> "cake"
"cake"
Tasty.
> "cake" + 3
<interactive>:1:0:
No instance for (Num [Char])
arising from a use of `+' at :1:0-9
Possible fix: add an instance declaration for (Num [Char])
In the expression: "cake" + 3
In the definition of `it': it = "cake" + 3
Now that's interesting. "What are you doing?!" Haskell cries. "Why do you try to add 3 to cake? What does that even mean, you very silly person?" Haskell complains because the type of the function + (Yes, it's a function. You can do anything with it that you can do with any other function) doesn't match what it sees. Important Bit Of Information Number 1a: Functions have types. In ghci, you can find the type of something with :t. Like so:
> :t (+)
(+) :: (Num a) => a -> a -> a
Okay, first, why + is in parentheses. It's an infix function, and those need to be in parentheses to be passed around. Now, to explain the second line.
(+) :: (Num a) => a -> a -> a
First of all, Num. This is what's called a type class. Num is a class containing all the numeric types. (Num a) means that, for this type signature, a is a numeric type.
a -> a -> ameans that the function takes two arguments of type a and returns a value of type a. So, + is a function that takes two numeric arguments and returns a numeric value.
Let's play around a bit more with :t.
> :t 'e'
'e' :: Char
A character is denoted by single quotes.
> :t "cake"
"cake" :: [Char]
That's a list of characters. In Haskell, there's no difference between this and a string. (More on lists later)
> :t 3
3 :: (Num t) => t
Without any context, 3 doesn't have a specific type. There are quite a few numeric types, and Haskell doesn't know which one we want, so, for now, it's just some kind of number.
> :t succ
succ :: (Enum a) => a -> a
succ is a function that takes a value and returns the next one. Enum is a type class containing types where "next value" actually means something. You can use these types in ranges (more on that later).
:t print
print :: (Show a) => a -> IO ()
print does exactly what you think it does. Show is a typeclass containing things you can print. The weird part here is
IO ()This is what's called a monad. They're weird. Don't worry about them for now.
:t (<)
(<) :: (Ord a) => a -> a -> Bool
< returns True if the first value is less, False otherwise. Bool is, obviously, the type for boolean values. Ord is the type class containing types whose values are in a defined order.
Subscribe to:
Posts (Atom)